







Open source machine-learning algorithms for the prediction of optimal cancer drug therapies
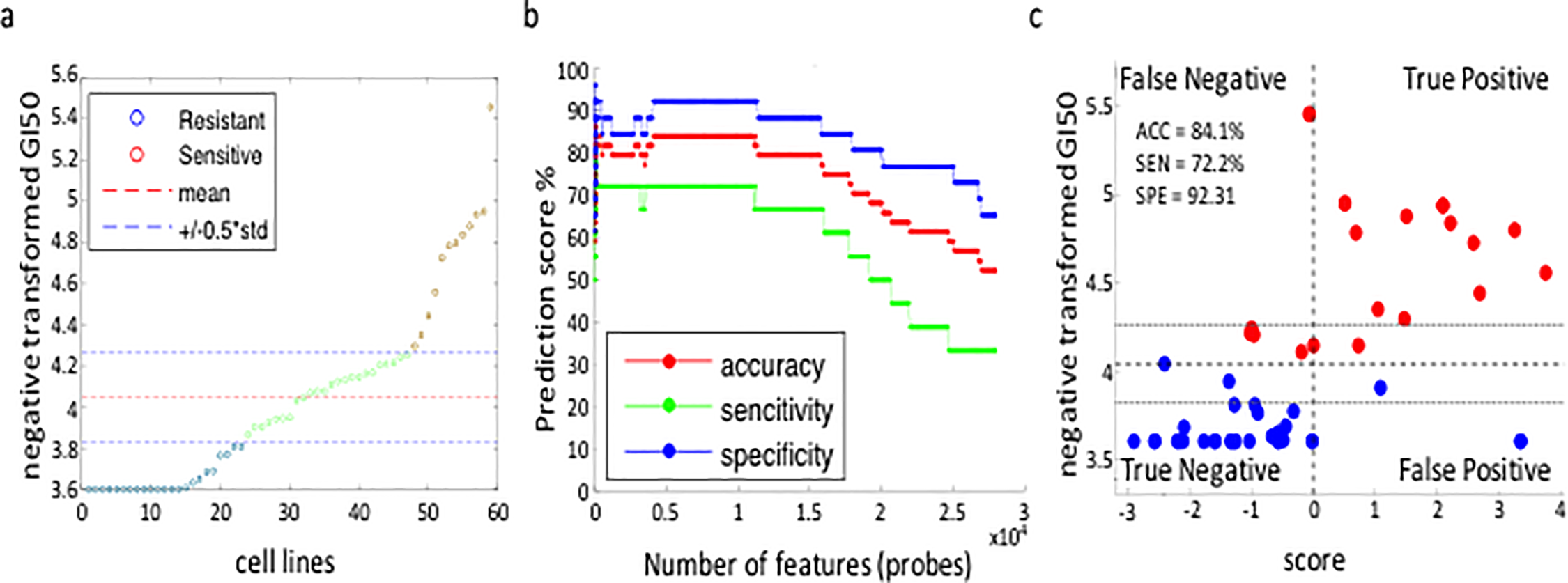
Precision medicine is a rapidly growing area of modern medical science and open source machine-learning codes promise to be a critical component for the successful development of standardized and automated analysis of patient data. One important goal of precision cancer medicine is the accurate prediction of optimal drug therapies from the genomic profiles of individual patient tumors. We introduce here an open source software platform that employs a highly versatile support vector machine (SVM) algorithm combined with a standard recursive feature elimination (RFE) approach to predict personalized drug responses from gene expression profiles. Drug specific models were built using gene expression and drug response data from the National Cancer Institute panel of 60 human cancer cell lines (NCI-60). The models are highly accurate in predicting the drug responsiveness of a variety of cancer cell lines including those comprising the recent NCI-DREAM Challenge. We demonstrate that predictive accuracy is optimized when the learning dataset utilizes all probe-set expression values from a diversity of cancer cell types without pre-filtering for genes generally considered to be “drivers” of cancer onset/progression. Application of our models to publically available ovarian cancer (OC) patient gene expression datasets generated predictions consistent with observed responses previously reported in the literature. By making our algorithm “open source”, we hope to facilitate its testing in a variety of cancer types and contexts leading to community-driven improvements and refinements in subsequent applications.
