







A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research — An International Collaboration
Abstract
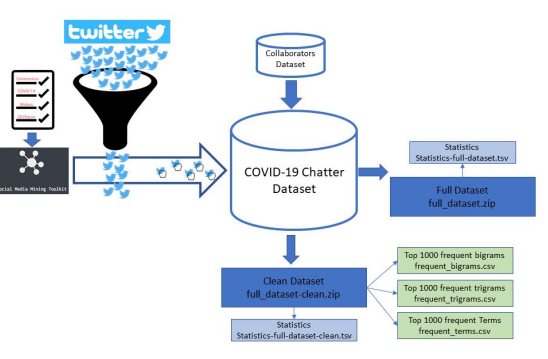
As the COVID-19 pandemic continues its march around the world, an unprecedented amount of open data is being generated for genetics and epidemiological research. The unparalleled rate at which many research groups around the world are releasing data and publications on the ongoing pandemic is allowing other scientists to learn from local experiences and data generated in the front lines of the COVID-19 pandemic. However, there is a need to integrate additional data sources that map and measure the role of social dynamics of such a unique world-wide event into biomedical, biological, and epidemiological analyses. For this purpose, we present a large-scale curated dataset of over 152 million tweets, growing daily, related to COVID-19 chatter generated from January 1st to April 4th at the time of writing. This open dataset will allow researchers to conduct a number of research projects relating to the emotional and mental responses to social distancing measures, the identification of sources of misinformation, and the stratified measurement of sentiment towards the pandemic in near real time.
Authors: Juan M Banda, Ramya Tekumalla, Guanyu Wang, Jingyuan Yu, Tuo Liu, Yuning Ding, Gerardo Chowell

