







Apache Beam
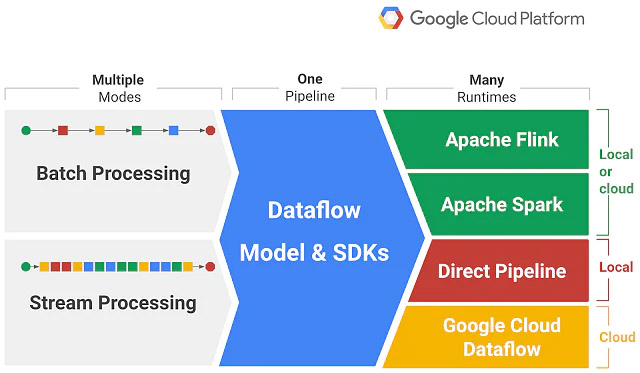
Apache Beam is an advanced unified programming open-source model launched in 2016. It derives its name “Beam” which is from “Batch” + “Stream” from its functionalities for both batch and streaming the parallel processing pipelines for data. To execute pipelines, beam supports numerous distributed processing back-ends, including Apache Flink, Apache Spark, Apache Samza, Hazelcast Jet, Google Cloud Dataflow, etc. It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programming languages: Java, Python, and Go.
Apache Beam has certain features that give an advantage to the user, the primary one being unified batch and streaming APIs with an increased level of abstraction and portability across runtimes. The only pitfalls are lesser transparency and control, the limited scope of performance improvement tricks compared to other Apache APIs, and open bugs.
You can contribute to Apache Beam open-source big data project here: https://github.com/apache/beam
