







CLEESE: An open-source audio-transformation toolbox for data-driven experiments in speech and music cognition
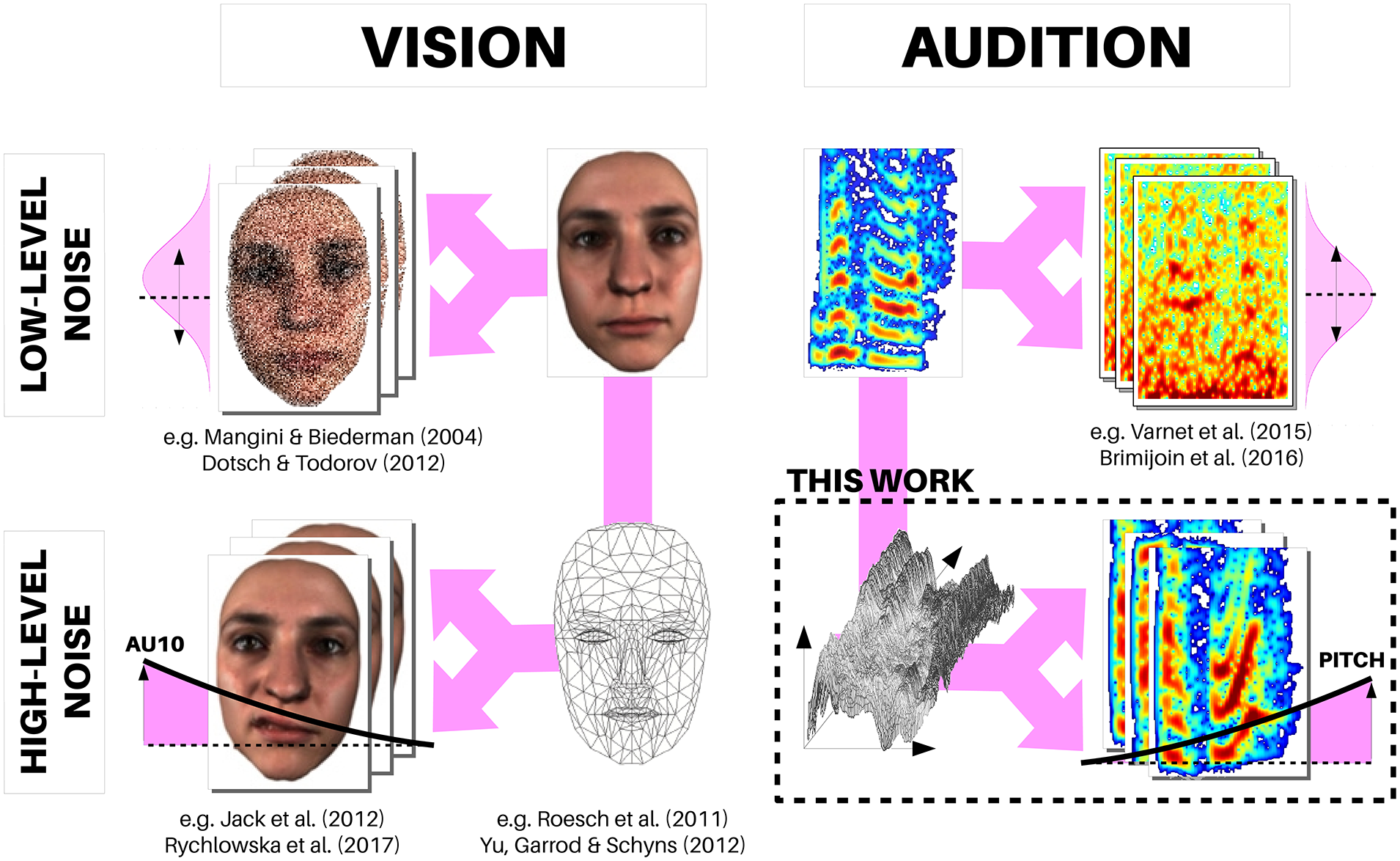
Over the past few years, the field of visual social cognition and face processing has been dramatically impacted by a series of data-driven studies employing computer-graphics tools to synthesize arbitrary meaningful facial expressions. In the auditory modality, reverse correlation is traditionally used to characterize sensory processing at the level of spectral or spectro-temporal stimulus properties, but not higher-level cognitive processing of e.g. words, sentences or music, by lack of tools able to manipulate the stimulus dimensions that are relevant for these processes. Here, we present an open-source audio-transformation toolbox, called CLEESE, able to systematically randomize the prosody/melody of existing speech and music recordings. CLEESE works by cutting recordings in small successive time segments (e.g. every successive 100 milliseconds in a spoken utterance), and applying a random parametric transformation of each segment’s pitch, duration or amplitude, using a new Python-language implementation of the phase-vocoder digital audio technique. We present here two applications of the tool to generate stimuli for studying intonation processing of interrogative vs declarative speech, and rhythm processing of sung melodies.
